Webservices
Introduction
Web Services mean many things to many people. In the end, there will be a set of standards which allow us to do things we could not do before, but in the mean time different people and companies approach them from different positions, and with different expectations. In 2001-2, Web Services have also been a buzzword used repeatedly and claimed to be one of the hot new technologies. The common themes are:-
- A departure from the web as a quasi-static information space to one in which interactions are the primary model
- A use of HTTP, XML and other standards from the web architecture as the building blocks
- A typical focus on enterprise wide and inter-enterprise operations
The Web in Web Services is, from the first point, a misuse: the term Internet Services would be more appropriate. The Web comes from the second point – the use of the HTTP and XML is already in use as a well-understood and well-debugged set of protocols which support the Web, and so it makes sense to reuse them in providing remote operations and those things connected with them. The third point is what makes web service requirements so different from a local RPC system. The fact that data is exchanged for business purposes and between different social entities means that accountability is required, rather than just reliable transmission.
- The vendors of software see web services as way to repackage existing capability in a way which makes it interoperable with other systems.
- The security requirements for web services are dictated by the trust environments, whether it is intranet or b2b or b2c, etc
- For b2b one needs not just reliabilioty but accountability.
The architecture of Web Services is the scope of the W3C Web Service Architecture Working Group.
The architecture uses the following diagram for the highest level:

However, the essential part of Web services is the Interact relationship between a Service provider and Service requestor. This is the Web Service. Discovery agencies need not be used – they will in some cases but not in others. The discovery agencies are well represented as a cloud, rather than being a well-defined module in the web services architecture. They will become interface to a huge world of data and query services which provide data about web services as well as many other things.The Interact between between requestor and provider is the essential defining element to web services. As we shall see, the metadata about web services
Technologies within the Web Servcies umbrella
There is a mass of different pieces being bolted onto the foundations of Web Services provided by WSDL and SOAP 1.2 and th diagram implies things considerably. The management layer is a supervisory layer allowing the conrol of the many agents involved in a web services-based operation. The “Application semantics” layer indicates the necessity, for any useful interoperability, to have
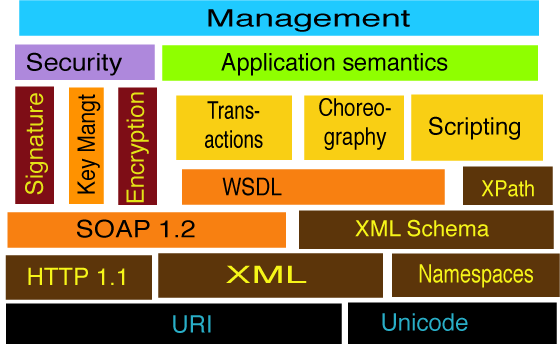
Run Time messaging
The design work of web services is divided between the run time protocols and the descriptions of services.
The W3C work at runtime based on HTTP transport of XML-encoded messages, using the SOAP protocol. (Here by SOAP we mean SOAP 1.2, previous versions including early proprietory submissions which are not standards or guaranteed to interoperate) . There is a bifurcation in the design at this point, as SOAP operates basically in two modes.
In one, the XML message is used to encode the parameters to a remote operation in much the same way as remote method invokation in for example, Corba, DCOM, or RMI. In this mode, XML is used as the marshalling style, but the system is a distributed using remote procedure call in a fairly traditional way.
- There is a standard marshalling syntax
- Interfaces between software modules have well-defined functions, which in turn have well-defined and typed input and output parameters
- Stubs (dummy routines which similate the remote procedure by a local one which communcates with the remote one) can be generated directly from the WSDl definition
- The remoteness can be transparent, making the design of a distributed system similar to the design of a program.
In the other mode, SOAP carries an XML document, and the task of the receiver is seen more as a document processing operation. This is less rigid than the RPC style.
- The interface a service provides is defined just by the XML schema. This defines the acceptable document types, which can allwo extension in many ways, using XML namespaces.
The communication is more apparent to the application writer, who deals with the document object model (DOM) of the recived message, rather than having parameters unmkarshalled automatically.
XML tools such as XSLT and XML-Query, and XML encryption and so on can be used.
It is simpler to use message exchange patterns other than the request/response.
The document mode of SOAP seems to be getting the most traction in the ecommerce stack. This is not an accident. The XML mode is more flexible than the RPC mode. It is easier in principle to extend an XML-based message system to include more information as a system grows. In fact, RDF is especially powerful in this area, as new information can be parsed into an entity-relationship form by old agents, and it becomes logically clear which parts can be ignored by those who do not understand them.
Functionality which has been mentioned as required above the basic layer at runtime includes:
- Routing. Routine data within message for processing bu different agents; defining workflow path of message. Black box or white box patterns of design.
- Security. Prolfiling existing security technologies for use in ebusiness applications using web sevices. Authentication and key management.
- Packaging of attachments to messages. XML Packaging.
- Reliable messaging (delivery, non-duplication, ordering) for the case in which the transport layer (such as TCP under the HTTP) doesnot provide this. (TCP does provide this reliability but (a) systems are not designed to keep TCP connections open for the weeks or years over which a web service may run, and (b) TCP does not provide accountability so you can show the tax man the acknowledgement of receipt 7 years later.)
Description
The descriptions of services are made at various different models and different levels of abstraction in different specs proposed as part of the stack, though there is agreement on WSDL as the modelling of the lowest level, the message or request/response interaction, and the binding to the specific HTTP (say) port at which it happens.

Higher layers in the description above WSDL are known variously as coordination, orchestration, choreography, composition.
They involve (compared with basic WSDL), for example:
- Protocols involving more than two messages
- Protocols having a common shared state over a long period
- Protocols having more than two parties involved; web service workflow
- structured version (ws-*, damls process model)
- precondition-postcondition style (DAMLS)
- The protocols as business protocols, in terms of common business functions
- The relationship between allowed transitions in the protocol and the content of messages. For example, the requirement for a transaction ID to match across a transaction, or for possible responses to be a function of a request code.
Composability and Choreography
Composability of web services refers to the building, from a set of web services, of something at a higher level, typically itself exposed as a larger web service.
Choreography refers more abstractly the part of the description of web services which defines a way, or the ways, in which a acyual invokations to various web services work together. (Peltz uses Choregraphy when it involves multiple parties, and Orchestration when it is internal to one party. Thus the former crosses application boundaries, the latter also crosses organization boundaries. here we use Choregorahy in general for both.)
There is so small amount overlap here, which has led to some confusion. To be general, one might say, for example, that a flight confirmation must involve an already reserved flight. This the actual constraint. One can describe a particular choregraphy (a particular dance, if you like) in which a flight query service is called, and produced a list of flights, and then a reservation service is called to reserve the flight, that is successful, and the resulting reservation is passed to the confirmation service. It may be that there are other ways — other choreographies — in which one could have achived a reserved flight. The engineer has the choice of modelling the many possible ways all in one choreogrpahy, or of making several choreographies.
Web services can be combined in such as way that messages are passed around in a very random fashion. However, a particular design techniqe is for a master process to delegate to other services in a recusive tree-like manner, as has been de rigueur in programming languages since Pascal. For example, if the consumer asks the travel agent and the the travel agent books a hotel, the hotel will reply to the travel agent, not to the consumer. This makes everything orderly.
WSCI, BPML and BEPL take this approach to choreography. This is a programming language approach with
- Sequential, Parallel and Exception execution, loops & conditionals
- Message-passing rendezvous between processes
- Calls: Web Services
- Data: bits of XML
- Assignment to variables
- Expressions: XPath 1.0 plugable in BPEL
- Does not handle actual calculations, rules etc.
WSCI has the empahsis on description, and BPEL on being able to compile to an executable agent. As neither is intended to do the actual calculations or business rules, it would be closer to compare themm with scripting shells such as bash which handle concurrency and synchronization but actually call programs (or rather web services) to do the real work.
Message-oriented choregraphy
The Paper Trail concept is that the state of a mult-agent multi-process system can be looked at, sometimes rather effectively, as a function of the documents which have been transmitted.
The process-oriented attitude to a bank-customer relationship may be “In parallel, the customer writes checks, merchants pay in checks, credit card transactions happen, all month. Then, the charges, interest are assessed and a bank statement sent from the bank to the customer”. The document-, or message-oriented one is more like “Every month a bank balance lists valid transaction dated that month. A cleared incoming check in a valid transaction. A cleared outgoing check is a valid transaction. A validated credit card debit is a valid transaction. A check is cleared if it is incoming and there is a matching transfer from the payee bank”, and so on. This builds the relationships up in a bottom-up, weblike way. The process-oriented attitude suggests the bank be written as a procedure in a top-down way using for example WSCI and BPL. The document-oriented attitude suggests the use of business rules systems triggered by the receipt of new information — new documents, in this case new web services messages.
(Web service messages are of course documents just like documents sent in email. Messages are particular in that they have a particular time of transmission, and their document content sdo not change. They do of course generally have identifiers, and even though they can only be accessed by sender and explicit receivers, they can still be regarded as part of the web by those parties.)
Whether the design process is a top-down process-oriented one or a bottom-up document-oriented one, the design will have to be translated into a set of agents and their responses to incoming messages. This manipulation can of course be done automatically.
A concern in all this frantic design is it evolution with time. A BPEL script sets out to be a description of a a business process at a high level. The critical values which decide on conditional execution, or which correlate a particular process with a given transaction, are expressed as parts of the structure of the XML messages. This may lead to what has been called “DTD fragility”. What happens which you change the DTD? The design of the message types with XML schema is the sort of thing which is difficult to get everyone in a company to agree on, and tents to change with time. There are many arbitrary choices made as to how the knowledge in the message is serialized as XML. Moving to RDF may, by removing a layer of arbitrary design, reduce that fragility and allow web sevice choregraphy to evolve with time within and outside a company.
Process modeling
When considering a business system with multiple agents and multiple concurrent processes, one would like to have an automated way of checking some fundamental questions.
- Will the process necessarily terminate?
- Will the service respond within a given time?
- Will the net gain from a sale always be positive?
- Will we ever promise to ship something we do not have in stock?
and so on.
The pi calculus and other calculi derived from it are formal ways of modeling systems with multiple agents and multiple processes. They can do some way to answering these questions. Rule-based systems can also be designed so that proofs can be found of these sort of conjecture. This is a good reason for keeping the languages involved as simple as possible It may be the design reason for the limitations on computational power in WSCI and BPEL.
See petri nets (IBM; and stadford), Pi calculus @@ refs.
Much of the functionality is seen in terms of tying web services down to well-known functionality such as exiting transaction processing systems, PKI trust infrastructure, and so on.
Discovery
In a large number of applications, web servcies will be provided by on one hand and used by on the other peers who have established relationships. Indeed, until a trust infrastructure is fairly developed it is not reasonable to expect computers to do automatic comparison shopping for very many services. Web services will probably (like the web in 1993, and the Semantic Web in 2003) spread first within the corporate firewall, where security problems are minor and mistakes less embarassing than inter-enterprise or publically. However, the goal is that so many web services should be available that it will be important to be able to find them in all kinds of ways.
The UDDI project and the related work on description and query systems is aimed at this. A positive aspect of UDDI is the definition of an ontology for web services. Problems with it are that it is centralized by design, both in the single-tree ontology, and in the design based fundamentally on a central registry, with inter-registry operation as a secondary thing.
From the semantic web point of view, web services are simply one aspect of the many things which will be searched for. Indeed, the fact that a web service is provided may in fact be rather incidental to the essential nature of the business item which is discovered — a trader in stocks, a seller of lawnmowers, and so on. The semantic web aims to describe any aspect of anything, including the catalogs, parts, materials, services organization, relationships and contracts. A query system which addresses web services only makes sense when smoothly integrated with the rest of the web of enterprise knowledge.
Web Services and Semantic Web
The question of the relationship between these two activities is constantly in the air.
- The whole description side is a clear semantic web application, and so long as XML languages are defined which introduced with english language specs but no RDF mapping, there is a potential ambiguity which will have to be resolved later in making that mapping, there is an inability to use common semnatic web tools, and there is cost down the road assuming semantci web tools will eventually be used. Essentailly, web serv ices become instant legacy technoplogy for the semantic web.
- The DAML-services collalition of researchers is tackling the job of service description at a higher level.
- Many things which are described as web services can in fact be described as the publication of a series of semantic web documents, just as the billing of a peer company is in reality effected by the issuance of an invoice.
- When Semantic Web agents query each other, they could use SOAP (though a direct encoding into an HTTP URI may also be effective).
- When Semantic Web agents update each other, they should use SOAP, running typically over HTTP POST.
The argument against integration of the technologies is mainly social. It is costly to coordinate very large groups. It is much more effcient to develop WS and SW independently. Neither side has a great incentive to take on the learning required to absorb the needs and potentials fo the other. Using technology in preparation by another group takes a great leap of faith, and does really add to the development time. These are real issues. So while it may take more effort in the long run, it is a better parallelization of the design task to allow web services and semantic web to proceed in together without a mandated link. (This was the apparent consesnsus of the W3C AC meeting in Nice, 2000/11)
That said, wherever overlap of expertise between the technologies occurs, those who form a bridge should do their best to make the conceptual differences as small as possble.
Service design tools
Most modern software design differentiates strongly between the design of an interface, and the design of the software which implements it.
Web services are required to be composable – you should be able to make a web service implmentation by building it out of component web services. At the low level, think of making a latittude/longitude to state code converter composed from a latittude/longitude to postal code converter and a postal code to state code converter. At a high level, think of a making a vacation being composed of resrvations of flights, hotels and entertainment.
Runtime System management
Real web services have multiple agents running commerical environments, in which downtime is expensive, and incorrect operation could be disasterous. The running, monitoring, provisioning and upgrading of such systems clearly requires tools, but their design is out of scope for this overview.
